
前回は、livedoorニュースコーパスの文書データセットをK近傍法で分類しました。
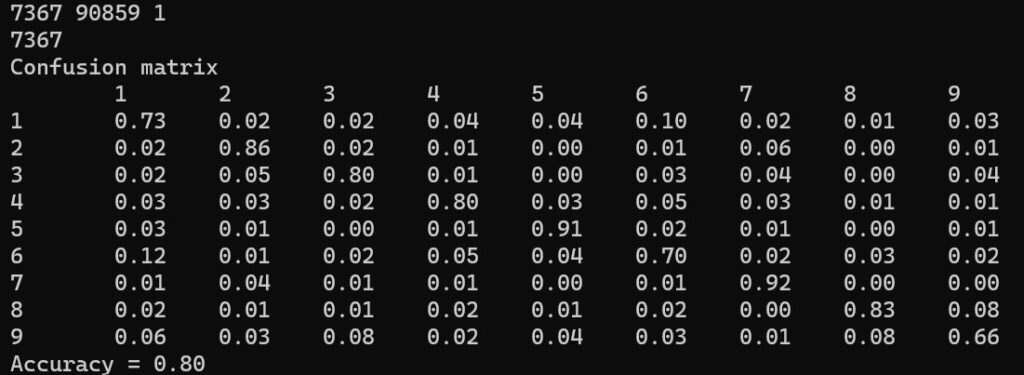
その分類結果が上記となったのですが、分類精度が低いものが幾つかあります。
- 73%:dokujo-tsushin
- 70%:peachy
- 66%:topic-news
そこで、これらカテゴリーの文書は全体的にどのような内容なのか確認して、分類を間違えてしまう原因を探してみます。
実験方法
各カテゴリーに属する文章を下記グループに分割し、重要単語を比較します。
- 正しく分類できた文書集合
- 正しく分類できなかった文書集合
dokujo-tsushinの場合
下記グループに分割して比較します。
- dokujo-tsushinの文書で、dokujo-tsushinと分類された文書集合
- dokujo-tsushinの文書で、dokujo-tsushinと分類されなかった文書集合
peachyの場合
下記グループに分割して比較します。
- peachyの文書で、peachyと分類された文書集合
- peachyの文書で、peachyと分類されなかった文書集合
topic-newsの場合
下記グループに分割して比較します。
- topic-newsの文書で、topic-newsと分類された文書集合
- topic-newsの文書で、topic-newsと分類されなかった文書集合
カイ二乗検定について
今回の場合、グループ1の方が文書数が多いため、重要単語の数をカウントするのではなく、割合で比較しようと思います。
重要単語の抽出には、カイ二乗検定の残差分析値を使用します。
この値を用いることで、数差による影響を考慮した評価が可能です。
2つの箱があると仮定します。
- 右の箱には100個のボールがあり、そのうち赤いボールが11個あった。
- 左の箱には10個のボールがあり、そのうち赤いボールが10個あった。
この場合、赤いボールが多くの割合を占めているのは当然左の箱ですが、数だけをカウントしてしまうと右の箱と判断されます。
今回は、
- 右の箱 = グループ1
- 左の箱 = グループ2
- ボール = 各文書の単語
- 赤ボール=各文書の重要単語
です。
実験結果
下記プログラムを使用して重要語を割り出し、どのような違いがあるか比較しました。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <unistd.h>
char **MatN, **MatL;
double *VecV;
int Dm, Dn, Dc, Dk, Dh, *VecA, **MatA, **MatX, *VecY, *VecB, *VecC;
void readValue(char *fn1/* lbl.txt */)
{
FILE *fp;
int i, j, k, h;
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
fscanf(fp, "%d %d %d", &Dm, &Dn, &Dc);
VecA = (int *) malloc(sizeof(int)*Dm);
MatA = (int **) malloc(sizeof(int *)*Dm);
MatX = (int **) malloc(sizeof(int *)*Dm);
for(i = 0; i < Dm; i++)
{
fscanf(fp, "%d", &VecA[i]);
MatA[i] = (int *) malloc(sizeof(int)*VecA[i]);
MatX[i] = (int *) malloc(sizeof(int)*VecA[i]);
for(j = 0; j < VecA[i]; j++)
{
fscanf(fp, "%d:%d", &k, &h);
MatA[i][j] = k-1;
MatX[i][j] = h;
}
while((j = getc(fp)) != EOF)
{
if(j == '\n')
break;
}
}
fclose(fp);
printf("%d %d %d\n", Dm, Dn, Dc);
}
void readValue2(char *fn1/* uid.txt */)
{
FILE *fp;
int i, j, k, c[3];
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
VecY = (int *) malloc(sizeof(int)*Dm);
for(i = 0; i < Dm; i++)
{
fscanf(fp, "%d", &VecY[i]);
while((j = getc(fp)) != EOF)
{
if(j == '\n')
break;
}
}
fclose(fp);
printf("%d\n", Dm);
// for(i = 0; i < Dm; i++) printf("%f\n", VecY[i]);
}
void readValue3(char *fn1/* wid.txt */)
{
FILE *fp;
int i, j;
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
MatL = (char **) malloc(sizeof(char *)*Dn);
for(i = 0; i < Dn; i++)
{
while((j = getc(fp)) != EOF)
{
if(j == ' ' || j == '\t')
break;
}
MatL[i] = (char *) malloc(sizeof(char)*1023);
for(j = 0; j < 1024; j++)
{
if((MatL[i][j] = getc(fp)) == ' ')
break;
}
MatL[i][j] = '\0';
while((j = getc(fp)) != EOF)
{
if(j == '\n')
break;
}
}
fclose(fp);
printf("%d\n", Dn);
}
void calValue(char *fn1/* important_word.txt */)
{
FILE *fp;
int i, j, k;
double p, v, y;
fp = fopen(fn1, "w");
VecB = (int *) malloc(sizeof(int)*Dn);
VecC = (int *) malloc(sizeof(int)*Dn);
VecV = (double *) malloc(sizeof(double)*Dn);
for(j = 0; j < Dn; j++)
{
VecB[j] = 0;
VecC[j] = 0;
VecV[j] = 0.0;
}
for(i = 0, y = 0.0; i < Dm; i++)
{
for(j = 0; j < VecA[i]; j++)
VecB[MatA[i][j]] += 1;
// 対象のカテゴリーではない場合
if(VecY[i] != Dk)
continue;
for(j = 0; j < VecA[i]; j++)
VecC[MatA[i][j]] += 1;
y += 1.0;
}
printf("%d\n", (int)y);
// カイ二乗検定で重要語を数値化
for(j = 0, v = y*(1.0-(y/Dm)); j < Dn; j++)
{
if((p = 1.0*VecB[j]/Dm) > 0.0)
VecV[j] = (VecC[j] - y * p) / sqrt(v * p * (1.0 - p));
}
// 重要語を上位から Dh 個ファイルに記録
for(k = 0; k < Dh; k++)
{
for(j = 0, v = 0.0; j < Dn; j++)
{
// 既存の最大値 < 最大値 なら最大値を更新
if(v < VecV[j])
{
v = VecV[j];
i = j;
}
}
VecV[i] = 0.0;
//fprintf(fp, "%d %s %e (%d/%d)\n", k+1, MatL[i], v, VecC[i], VecB[i]);
fprintf(fp,"%s\n",MatL[i]);
}
// 重要語を下位から Dh 個ファイルに記録
for(k = 0; k < Dh; k++)
{
for(j = 0, v = 0.0; j < Dn; j++)
{
// 既存の最小値 < 最小値 なら最小値を更新
if(VecV[j] < v)
{
v = VecV[j];
i = j;
}
}
// printf("%d %s %e (%d/%d)\n", k+1, MatL[i], v, VecC[i], VecB[i]);
VecV[i] = 0.0;
}
fclose(fp);
}
int main(int argc, char **argv)
{
readValue(argv[1]);
Dk = atoi(argv[3]);
readValue2(argv[2]);
readValue3(argv[4]);
Dh = 100;
calValue(argv[5]);
return 0;
}dokujo-tsushinの場合
図の左がグループ1で、右がグループ2です。
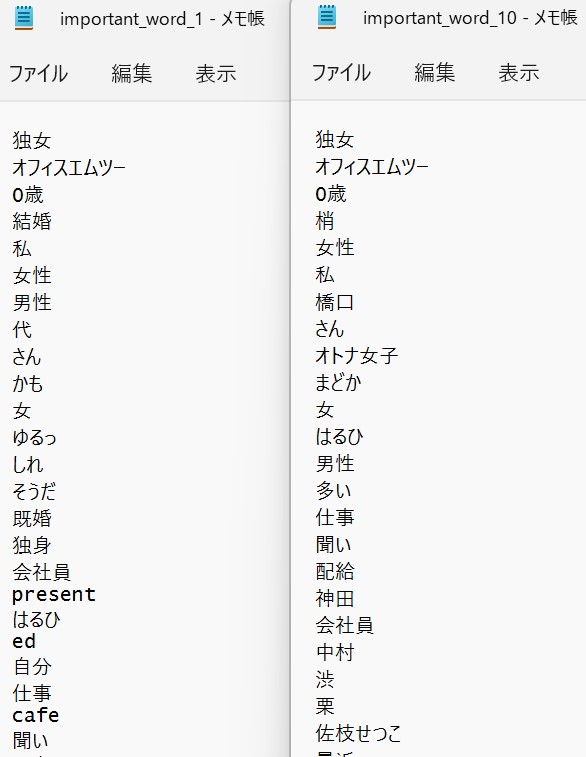
グループ1(左)では「かも」「そうだ」が重要語になっています。
↓
「~かも」「~そうだ」など砕けた言い方が多いことが分かります。
一方で、グループ2(右)では「かも」「そうだ」が重要語になっていません。
↓
砕けた表現がない文書だと分類を間違えてしまうケースがあるようです。
dokujo-tsushin であるかの判断基準は、
「砕けた表現が含まれているか」
である可能性が高い。
peachyの場合
左がグループ1で、右がグループ2です。

グループ2(右)の重要語がdokujo-tsushinと似ています。
↓
dokujo-tsushinで頻繫に出現する単語が重要単語と判断されている場合は、正しく分類できなくなっている可能性が高いです。
実際、分類結果の出力表を確認すると、peachyの分類で一番多かった誤りがdokujo-tsushinに分類しているケースであることが分かります。
内容が dokujo-tsushin と酷似している文書が一定数存在する。
topic-newsの場合
左がグループ1で、右がグループ2です。
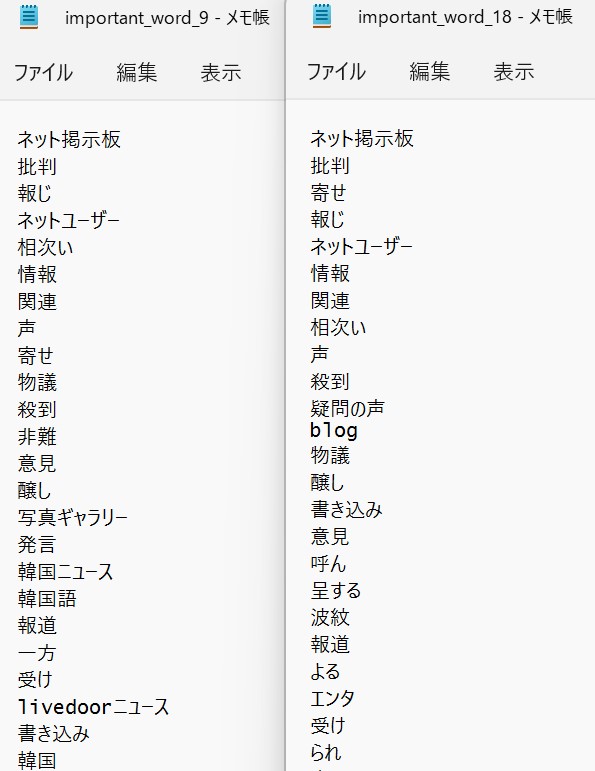
グループ2(右)の重要語から「韓国~」が消えています。
↓
単語「韓国」が無い=topic-newsでないと判断している可能性が高いです。
グループ1に「韓国ニュース」とか出ているので、韓国に関する記事が多いのかもしれません。
ニュース記事は韓国関連を題材にしたものが多く、文書内容に若干の偏りが見受けられる。
まとめ
今回は、K近傍法を用いた分類結果から、誤分類が多いカテゴリーに焦点を当て、間違えてしまう要因を分析しました。
その結果、カテゴリーが異なっていても文書内容は然程違いがなかったり、このカテゴリーには無さそうな単語が部分的に多く出現している等といった文書が見受けられ、そもそも元データの段階で不適切なカテゴリー分けがなされている文書が少なからず存在していそうです。
livedoorニュースコーパスの文書データセットは、7000件以上の文書を人手でカテゴリー分けすることで作成されたものだと思われるので、幾つかの文書に不適切なラベルが付与されてしまうこと自体は仕方がないのですが、自動化できたら文書データの全体像が容易に把握可能となり、データ分析が非常に楽になりそうです。
事情が少し分かったため、次回はカテゴリーを自動付与する方法を模索するなどして、もう少し詳しく調査してみます。


