
大学院では、文書検索に関する研究をすることになりましたが、大規模データ分析は全く経験がないので、進捗状況を見直せるよう記事にまとめておこうと思います。
なお、移籍することになった研究室はC言語をメインに使用しているため、それに倣ってC言語で実装します。
文書データ
研究ではlivedoorニュースコーパスを使用します。

ダウンロード - 株式会社ロンウイット
DOWNLOADS
www.rondhuit.com
ここから全文書を分かち書きして単語辞書を作成します。
分かち書き
文章中に出現する各単語の間に空白を入れる「分かち書き」と呼ばれる処理をします。

単語ごとに分割することで、単語辞書の作成や出現頻度のカウントが簡単に出来ます。
今回は下記プログラムを使用しました。
# coding: utf-8
def wakachi(text):
# 分かち書き : '-O wakati' ,
tagger = MeCab.Tagger(r'-Owakati -d "/usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"')
try:
res = tagger.parse(text.strip())
except:
return []
return res
f1 = open("/content/drive/MyDrive/express/test.csv", 'r', encoding = "utf-8", newline = '')
f2 = open("/content/drive/MyDrive/express/wakachi.csv", 'w', encoding = "utf-8", newline = '')
line = f1.readline()
while line:
line += line.strip()
line = line.replace(',', '、')
line = line.replace('\t', '')
line = wakachi(line)
line = line.replace("\n",'')
f2.write(line)
line = f1.readline()
f1.close()
f2.close()分かち書き処理ではmecab-ipadic-NEologdをインストールして用いています。
なお、コレを使うためだけにpythonプログラムでコーディングしました。
以降のセクションではC言語を使います。
mecab-ipadic-NEologdについて
Web上の言語資源から得た新語を追加することで最近の言葉にも対応できるようにした MeCab 用のシステム辞書です。
ここからダウンロードしてます。
・mecab-ipadic-NEologd : Neologism dictionary for MeCab
単語辞書を作成
分かち書きした全文書データから、全単語の単語IDをC言語で作成します。
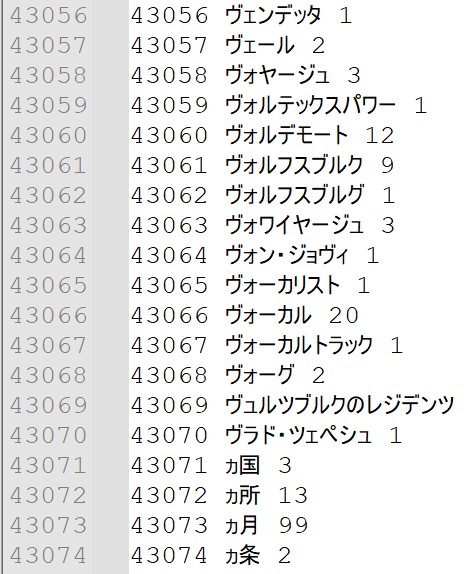
単語IDの作成には下記プログラムを使用しました。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <string.h>
#include <unistd.h>
char *str_list, **cmp_list1;
int *index_list, *sort_part;
int new_line_count, space_count;
/*wakachi.txt を呼び出し内容を記録する*/
void read_word(char *f_name)
{
FILE *fp;
int i, j, k, c;
if((fp = fopen(f_name, "r")) == NULL)
{
printf("Unknown File = %s\n", f_name);
exit(1);
}
new_line_count = 0;
space_count = 0;
while((c = getc(fp)) != EOF)
{
if(c == ' ') space_count +=1;
if(c == '\n') new_line_count +=1;
}
fclose(fp);
space_count += new_line_count;
printf("%d %d\n", new_line_count, space_count);
fp = fopen(f_name, "r");
cmp_list1 = (char **) malloc(sizeof(char *)*space_count);
str_list = (char *) malloc(sizeof(char)*4096);
i = 0;
j = 0;
while((c = getc(fp)) != EOF)
{
if(c == ' ' || c == '\n')
{
if(j == 0)
continue;
cmp_list1[i] = (char *) malloc(sizeof(char)*(j+1));
for(k = 0; k < j; k++) {
cmp_list1[i][k] = str_list[k];
printf("%c ", cmp_list1[i][k]);
}
printf("\n");
cmp_list1[i++][j] = '\0';
j = 0;
}
else
str_list[j++] = c;
}
fclose(fp);
printf("%d\n", i);
space_count = i;
}
/* 並べ替え */
void s_room_sort(int *ip, int n)
{
int i, j, k, h;
if((h = n/2) == 0) return;
s_room_sort(&ip[0], h);
s_room_sort(&ip[h], n-h);
for(i = j = 0, k = h; i < n; i++)
{
if(j < h && (k == n || strcmp(cmp_list1[ip[j]], cmp_list1[ip[k]]) <= 0))
sort_part[i] = ip[j++];
else
sort_part[i] = ip[k++];
}
for(i = 0; i < n; i++)
ip[i] = sort_part[i];
}
/* wid.txt を呼び出し内容を記録する*/
void print_id(char *f_name)
{
FILE *fp;
int h, i, k, pos, next_pos;
index_list = (int *) malloc(sizeof(int)*space_count);
sort_part = (int *) malloc(sizeof(int)*space_count);
for(i = 0; i < space_count; i++)
index_list[i] = i;
s_room_sort(&index_list[0], space_count);
fp = fopen(f_name, "w");
for(h = i = 0; i < space_count; )
{
pos = index_list[i];
for(next_pos = i+1, k = 1; next_pos < space_count; next_pos++)
{
if(strcmp(cmp_list1[pos], cmp_list1[index_list[next_pos]]) == 0)
k++;
else
break;
}
fprintf(fp, "%d %s %d\n", h+1, cmp_list1[pos], k);
i = next_pos;
h++;
}
fclose(fp);
}
int main(int argc, char **argv)
{
read_word(argv[1]); //wakachi.txt
print_id(argv[2]); //wid.txt
return 0;
}単語出現頻度表を作成
さらに、各文書での単語の出現回数も記録しておきます。
これがあると、特徴量抽出の際に各文書の単語出現頻度を特徴量として使用できるので便利です。
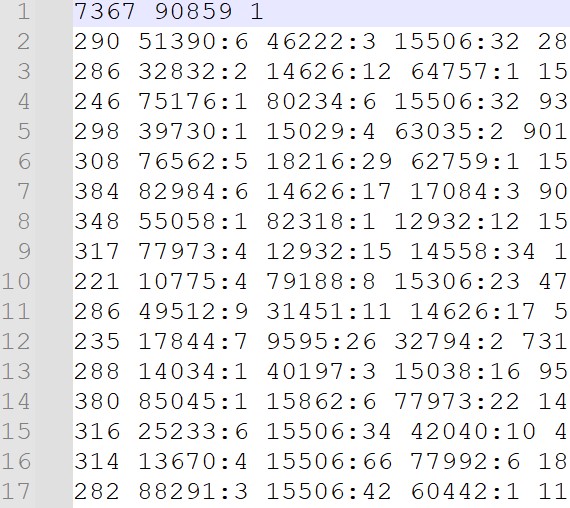
下記プログラムを使用しました。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include <string.h>
char *word, **word_list;
int wakachi_count, word_count;
int *roop_list, **index_list, *result_sort, *count_list;
/* wid.txt を呼び出し内容を記録する*/
void read_word(char *f_name)
{
FILE *fp;
int c, i, j, k;
if((fp = fopen(f_name, "r")) == NULL){
printf("Unknown File = %s\n", f_name);
exit(1);
}
word_count = 0;
while((c = getc(fp)) != EOF){
if(c == '\n')
word_count +=1;
}
fclose(fp);
printf("%d\n", word_count);
word = (char *) malloc(sizeof(char)*4096);
word_list = (char **) malloc(sizeof(char *)*word_count);
fp = fopen(f_name, "r");
for(i = 0; i < word_count; i++){
while((c = getc(fp)) != EOF){
if(c == ' ')
break;
}
for(j = 0; j < 4096; j++){
if((word[j] = getc(fp)) == ' ')
break;
}
while((c = getc(fp)) != EOF){
if(c == '\n')
break;
}
word_list[i] = (char *) malloc(sizeof(char)*(j+1));
for(k = 0; k < j; k++) word_list[i][k] = word[k];
word_list[i][j] = '\0';
}
fclose(fp);
printf("%d\n", word_count);
}
int s_room_sort(char *np, int b, int e)
{
int c, v;
// if(b == e){ printf("unknown\n"); return(-1);}
if(b == e) return(-1);
c = b + ((e-b)/2);
v = strcmp(np, word_list[c]);
if(v == 0) return(c);
else if(v < 0) return(s_room_sort(np, b, c));
else return(s_room_sort(np, c+1, e));
}
/* wakachi.txt を呼び出し内容を記録する */
void read_wakachi(char *f_name)
{
FILE *fp;
int c, i, j, k;
if((fp = fopen(f_name, "r")) == NULL){
printf("Unknown File = %s\n", f_name);
return;
}
wakachi_count = 0;
while((c = getc(fp)) != EOF){
if(c == '\n')
wakachi_count +=1;
}
fclose(fp);
printf("%d\n", wakachi_count);
roop_list = (int *) malloc(sizeof(int)*wakachi_count);
index_list = (int **) malloc(sizeof(int *)*wakachi_count);
fp = fopen(f_name, "r");
i = 0;
j = 0;
k = 0;
while((c = getc(fp)) != EOF){
if( (c == ' ') && (j > 0) ){
word[j] = '\0';
result_sort[k++] = s_room_sort(word, 0, word_count);
j = 0;
}
else if(c == '\n'){
if(j > 0){
word[j] = '\0';
result_sort[k++] = s_room_sort(word, 0, word_count);
}
roop_list[i] = k;
index_list[i] = (int *) malloc(sizeof(int)*k);
for(j = 0; j < k; j++) index_list[i][j] = result_sort[j];
i++;
j = 0;
k = 0;
}
else word[j++] = c;
}
fclose(fp);
printf("%d\n", i);
}
/* 各単語に対応する単語番号を lbl.txt に登録 */
void write_mining(char *f_name)
{
FILE *fp;
int word_id, i, j, k;
for(i = 0; i < word_count; i++) count_list[i] = 0;
fp = fopen(f_name, "w");
fprintf(fp, "%d %d 1\n", wakachi_count, word_count);
for(i = 0; i < wakachi_count; i++){
for(j = k = 0; j < roop_list[i]; j++){
word_id = index_list[i][j];
if(count_list[word_id] != 0){
count_list[word_id] += 1;
continue;
}
result_sort[k++] = word_id;
count_list[word_id] = 1;
}
fprintf(fp, "%d ", k);
for(j = 0; j < k; j++){
word_id = result_sort[j];
fprintf(fp, "%d:%d ", word_id+1, count_list[word_id]);
count_list[word_id] = 0;
}
fprintf(fp, "\n");
}
fclose(fp);
}
int main(int argc, char **argv)
{
int i, j, k;
read_word(argv[1]);//wid.txt
result_sort = (int *) malloc(sizeof(int)*word_count);
count_list = (int *) malloc(sizeof(int)*word_count);
read_wakachi(argv[2]);//doc.txt
write_mining(argv[3]);//lbl.txt
return 0;
}まとめ
今回は、ダウンロードした文書データから「分かち書き」を利用して下記を作成しました。
- 全文書から抽出した単語辞書
- 各文書ごとの単語出現頻度表
次回では、これらの分析データを用いてK近傍法で文書分類してみます。


