
前回は各文書を分かち書きして単語辞書と単語出現頻度表を作成しました。
今回は、各文書ごとのTF-IDFベクトルからコサイン類似度を計算し、その値を用いてK近傍法で文書分類します。
TF-IDF
概念
TF-IDFは、各文書中に存在する各単語が、「どれくらい重要か」を示しています。
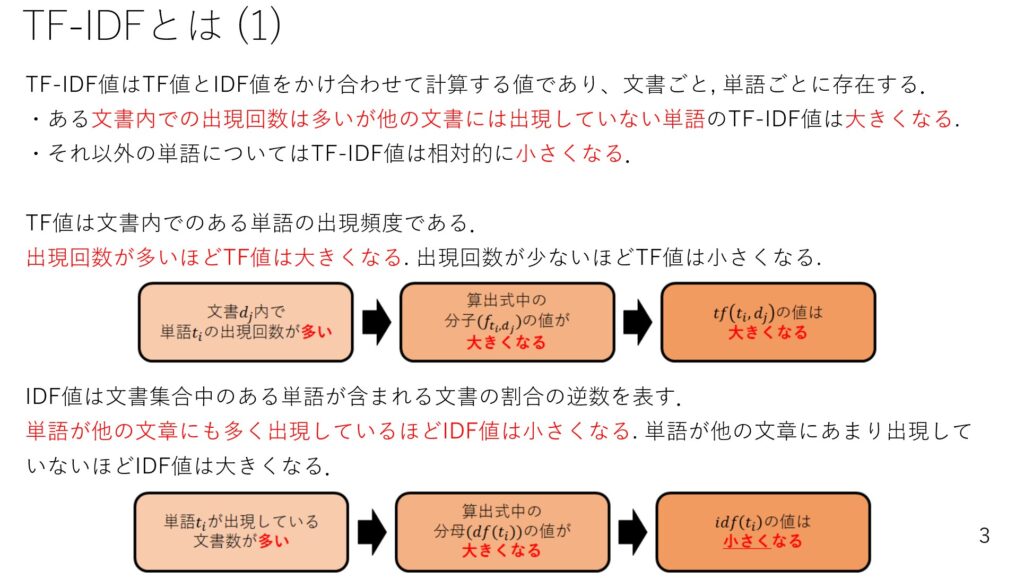
計算式は下記のとおりです。
TF×IDFなので、TF-IDFと呼ばれています。

TF-IDF値が高いほど重要単語とみなされます。
実装
下記プログラムのcalTFIDF関数を使用して、各文書のTF-IDFベクトルを計算しました。
/*TF-IDFを計算する*/
void calTFIDF(char *fn1)
{
int i, j;
double v;
FILE *fp1;
fp1 = fopen(fn1, "w");
/*------------------------------------------------------------------------*/
// IDF の計算
for(j = 0, v = log(1.0*N); j < V; j++)
VecW[j] = v;
for(j = 0; j < V; j++)
VecW[j] -= log(1.0*VecB[j]);
/*
VecW[j]にlog(1.0*N)を代入
↓
j < v の場合
VecW[j]からlog(1.0*VecB)を減算
logの割算を、減算を繰り返すことで実現している
IDF = log(1.0*N) / 単語wordの出現回数
*/
/*------------------------------------------------------------------------*/
int z, count = 0;
// 全文書のコサイン類似度を計算(ここの計算を色々いじって研究報告する → 文書分類に適した計算方法を分析する)
for(i = 0; i < N; i++)
{
// TF-IDF の計算
for(j = 0; j < VecA[i]; j++)
MatX[i][j] *= VecW[MatA[i][j]];
/*
j < 一つの文書中の単語数 の場合
MatX[i][j] に VecW[MatA[i][j]] を乗算
↓
単語の出現回数 * VecW[単語ID]
↓
TF * IDF
これより、MatX は TF-IDF となる
*/
// TF-IDF を記録
fprintf(fp1, "%s ", MatN[i]);
for(j = 0; j < VecA[i]; j++)
fprintf(fp1, "%d:%e ", MatA[i][j]+1, MatX[i][j]);
fprintf(fp1, "\n");
// 繰り返し(j < 一つの文書中の単語数)
for(j = 0, v = 0.0; j < VecA[i]; j++)
v += MatX[i][j] * MatX[i][j];
/* j < 一つの文書中の単語数 まで繰り返し
v に TF-IDF * TF-IDF を加算
↓
v = v + MatX[i][j] * MatX[i][j]
*/
// 繰り返し(j < 一つの文書中の単語数)
for(j = 0, v = 1.0/sqrt(v); j < VecA[i]; j++)
MatX[i][j] *= v;
/* v = 1.0/sqrt(TF-IDF*TF-IDF)
j < 一つの文書中の単語数 の場合
MatX[i][j](TF-IDF) に v を乗算
↓
MatX[i][j] = TF-IDF * 1.0/sqrt(TF-IDF*TF-IDF)
↑ ↑
任意の単語 全ての単語
*/
}
/*------------------------------------------------------------------------*/
fclose(fp1);
}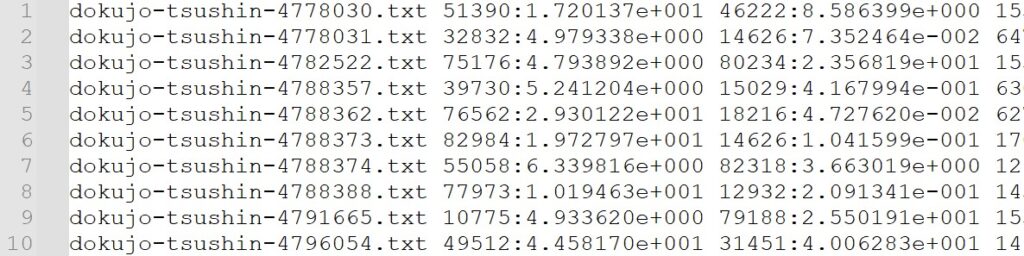
最初の文書を例にすると、単語ID51390番のTF-IDF値が1.720137e+001であることを示しています。
K近傍法
概念
K近傍法とは、自身の周囲にあるデータがどこに分類されているか集計を取り、多数決で自身の分類先を決定する方法です。
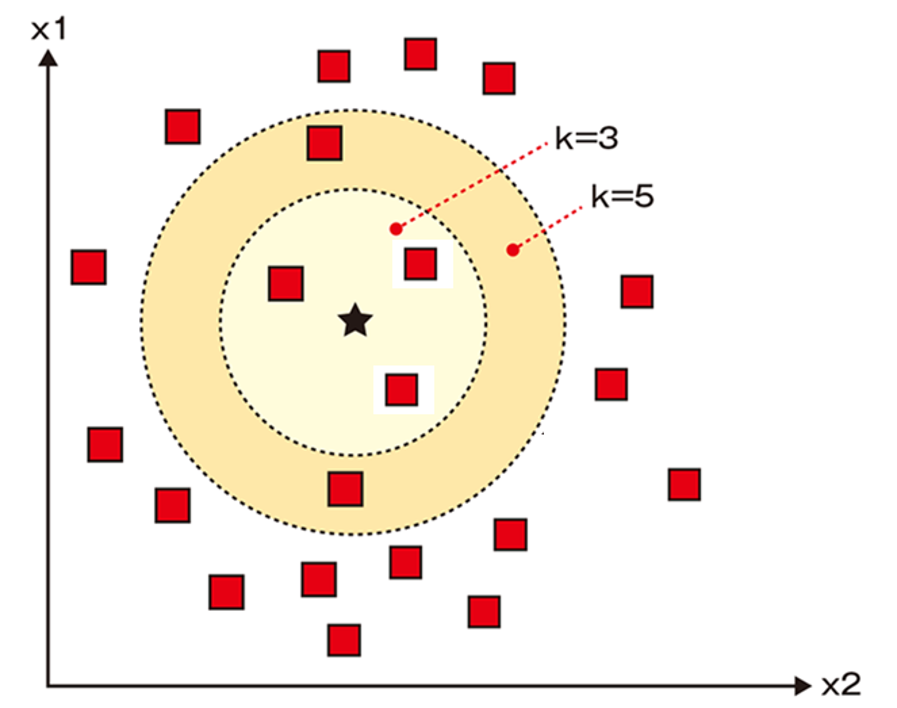
なお、Kは「幾つのデータで分類先を決めるか」を示す数値です。
コサイン類似度
ここの計算で、先ほど求めた各文書のTF-IDFベクトルを使います。
K近傍法では、周囲にある文書の分類先を多数決で決定するため、周囲にある文書がどれなのか把握する処理が必要です。
そこで使用するのがコサイン類似度です。
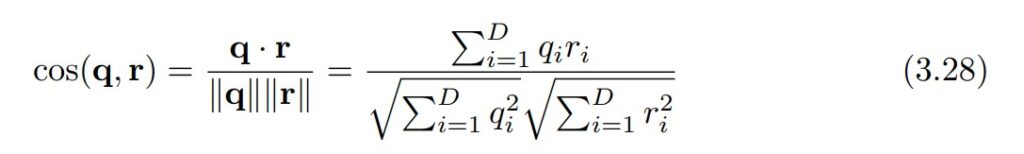
コサイン類似度を用いることで各文書間の類似度を計算できるため、この値を用いて文書分類していきます。
実装
下記プログラムを用いて文書分類します。
livedoorニュースコーパスは9種類にカテゴリー分けされているので、同じように9カテゴリー用意して分類するように調整しています。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
char **MatN;
int N, V, C, K, *VecA, **MatA, *VecB, **MatB, *VecC, **MatQ;
double **MatX, **MatY, *VecW, *VecZ;
/*lbl.txtの内容を記録する*/
void readValue(char *fn1)
{
FILE *fp;
int i, j, k;
double v;
/*-----------------------------------------------------------------------------------*/
// ファイルが無い場合は異常終了する
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
fscanf(fp, "%d %d %d", &N, &V, &C);
/*
以下の数値を入力する
文書数 : 7367 単語数 : 75024 カテゴリー数 : 1
fscanf(第一引数,第二引数,第三引数)
第一引数 : 読み取るファイル
第二引数 : どんな型で読み込むか
第三引数 : 第二引数を代入する変数
/*-----------------------------------------------------------------------------------*/
VecA = (int *) malloc(sizeof(int)*N);
MatA = (int **) malloc(sizeof(int *)*N);
MatX = (double **) malloc(sizeof(double *)*N);
/*
malloc関数でメモリを動的に割当てる
サイズ = int型のサイズ * N / int型のサイズ
N は文書の数とする
/*-----------------------------------------------------------------------------------*/
// 単語ID,出現回数の割り当て
for(i = 0; i < N; i++)
{
fscanf(fp, "%d", &VecA[i]);
MatA[i] = (int *) malloc(sizeof(int)*VecA[i]);
MatX[i] = (double *) malloc(sizeof(double)*VecA[i]);
for(j = 0; j < VecA[i]; j++)
{
// :の左側はint型,:の右側はdouble型で読み込む
fscanf(fp, "%d:%lf", &k, &v);
MatA[i][j] = k-1;
MatX[i][j] = v;
}
}
/*-----------------------------------------------------------------------------------*/
/* ------------------------------------------------------
i は以下を満たす自然数である
0 <= i <= 文書数
VecA[i]には以下のデータを格納する
VecA[i] : 一つの文書の単語数 ・・・ (A)
------------------------------------------------------
j は以下を満たす自然数である
0 <= j <= VecAの要素数
MatA[i][j], MatX[i][j]は次のように定義する
MatA[i][j] : 一つの文書に出現する一つの単語の単語ID ・・・ (B)
MatX[i][j] : MatA[i][j]の出現回数
(A),(B)より、VecAの要素数 == jの要素数 である
------------------------------------------------------
例 : 文書数 == 7367, 最初の文書にある単語数 == 177 の場合
MatA[i], MatX[i]におけるiの範囲 : 0 ~ 7366
MatA[i][j], MatX[i][j]におけるjの範囲 : 0 ~ 176
------------------------------------------------------
k,v に次の値を格納する
k = 単語ID
v = 出現回数
-------------------------------------------------------
例 : 単語ID == 47618, 出現回数 == 6 の場合
k = 47618
v = 6
-------------------------------------------------------
従って、一つの任意の単語をwordとすると、MatA,MatXには次の値が格納される
MatA[i][j] = wordの単語ID
MatX[i][j] = wordの出現回数 ・・・ (C)
(C)より、 MatX は TF-IDF の TF である
-------------------------------------------------------
*/
fclose(fp);
printf("%d %d %d \n", N, V, C);
}
/*uid.txtの内容を読み込む*/
void readName(char *fn1)
{
FILE *fp;
int i, j, k;
double v;
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
/*-----------------------------------------------------------------------------------*/
// 配列のサイズを割り当てる(Nは文書数)
VecC = (int *) malloc(sizeof(int)*N);
MatN = (char **) malloc(sizeof(char *)*N);
/*-----------------------------------------------------------------------------------*/
for(i = 0; i < N; i++){
fscanf(fp, "%d ", &VecC[i]);
/*
VecCにはカテゴリー番号1~8が格納される
以下にカテゴリーとカテゴリー番号の対応を示す
1 dokujo-tsushin
2 it-life-hack
3 kaden-channel
4 livedoor-homme
5 movie-enter
6 peachy
7 smax
8 sports-watch
9 topic-news
*/
MatN[i] = (char *) malloc(sizeof(char)*8191);
for(j = 0; j < 8192; j++)
{
if((MatN[i][j] = getc(fp)) == '\n')
break;
}
MatN[i][j] = '\0';
/*
i,j は以下を満たす自然数である
0 <= i <= 7367
0 <= j <= 8192
MatN には以下のデータを格納する
MatN[i] : ファイル名
MatN[i][j] : ファイル名の一文字
*/
}
/*-----------------------------------------------------------------------------------*/
fclose(fp);
printf("%d\n",N);
}
void initData()
{
int i, j;
/*------------------------------------------------------------------------*/
// 配列のサイズを割り当てる
VecB = (int *) malloc(sizeof(int)*V);
MatB = (int **) malloc(sizeof(int *)*V);
MatY = (double **) malloc(sizeof(double *)*V);
/*
Vは全文書の総単語数であり、readValue内で処理されている。
ポインタで処理しているのでどの関数からでも参照可能である。
*/
/*------------------------------------------------------------------------*/
for(j = 0; j < V; j++)
VecB[j] = 0;
for(i = 0; i < N; i++){
for(j = 0; j < VecA[i]; j++)
VecB[MatA[i][j]]++;
}
/* 繰り返し条件
i < N かつ j < VecA[i] の場合
↓
i < 文書数 かつ j < 一つの文章の単語数 の場合
↓
VecB[単語ID]に1加算
VecB : 一つの任意の単語が何個の文章に出現するのかを記録する
/*------------------------------------------------------------------------*/
// MatB,MatYの要素にメモリを割り当てる
for(j = 0; j < V; j++){
MatB[j] = (int *) malloc(sizeof(int)*VecB[j]);
MatY[j] = (double *) malloc(sizeof(double)*VecB[j]);
}
for(i = C = 0; i < N; i++)
{
if(VecC[i] > C)
C = VecC[i];
VecC[i]--;
}
// MatQにメモリを割り当てる
MatQ = (int **) malloc(sizeof(int *)*C);
for(i = 0; i < C; i++){
MatQ[i] = (int *) malloc(sizeof(int)*C);
for(j = 0; j < C; j++) MatQ[i][j] = 0;
}
// VecW, VecZにメモリを割り当てる
VecW = (double *) malloc(sizeof(double)*V);
VecZ = (double *) malloc(sizeof(double)*N);
/*-------------------------------------------------------------------------*/
}
/*TF-IDFを計算する*/
void calTFIDF(char *fn1)
{
int i, j;
double v;
FILE *fp1;
fp1 = fopen(fn1, "w");
/*------------------------------------------------------------------------*/
// IDF の計算
for(j = 0, v = log(1.0*N); j < V; j++)
VecW[j] = v;
for(j = 0; j < V; j++)
VecW[j] -= log(1.0*VecB[j]);
/*
VecW[j]にlog(1.0*N)を代入
↓
j < v の場合
VecW[j]からlog(1.0*VecB)を減算
logの割算を、減算を繰り返すことで実現している
IDF = log(1.0*N) / 単語wordの出現回数
*/
/*------------------------------------------------------------------------*/
int z, count = 0;
// 全文書のコサイン類似度を計算(ここの計算を色々いじって研究報告する → 文書分類に適した計算方法を分析する)
for(i = 0; i < N; i++)
{
// TF-IDF の計算
for(j = 0; j < VecA[i]; j++)
MatX[i][j] *= VecW[MatA[i][j]];
/*
j < 一つの文書中の単語数 の場合
MatX[i][j] に VecW[MatA[i][j]] を乗算
↓
単語の出現回数 * VecW[単語ID]
↓
TF * IDF
これより、MatX は TF-IDF となる
*/
// TF-IDF を記録
fprintf(fp1, "%s ", MatN[i]);
for(j = 0; j < VecA[i]; j++)
fprintf(fp1, "%d:%e ", MatA[i][j]+1, MatX[i][j]);
fprintf(fp1, "\n");
// 繰り返し(j < 一つの文書中の単語数)
for(j = 0, v = 0.0; j < VecA[i]; j++)
v += MatX[i][j] * MatX[i][j];
/* j < 一つの文書中の単語数 まで繰り返し
v に TF-IDF * TF-IDF を加算
↓
v = v + MatX[i][j] * MatX[i][j]
*/
// 繰り返し(j < 一つの文書中の単語数)
for(j = 0, v = 1.0/sqrt(v); j < VecA[i]; j++)
MatX[i][j] *= v;
/* v = 1.0/sqrt(TF-IDF*TF-IDF)
j < 一つの文書中の単語数 の場合
MatX[i][j](TF-IDF) に v を乗算
↓
MatX[i][j] = TF-IDF * 1.0/sqrt(TF-IDF*TF-IDF)
↑ ↑
任意の単語 全ての単語
*/
}
/*------------------------------------------------------------------------*/
fclose(fp1);
}
void calInverted()
{
int i, j, k;
// 繰り返し(j < 全文書の総単語数)
for(j = 0; j < V; j++)
VecB[j] = 0;
// 繰り返し(i < 文書数)
for(i = 0; i < N; i++)
{
// 繰り返し(j < 任意の文書の単語数)
for(j = 0; j < VecA[i]; j++)
{
k = MatA[i][j];
MatB[k][VecB[k]] = i;
MatY[k][VecB[k]++] = MatX[i][j];
/* k = 単語ID
MatB[単語ID][0] = i
MatY[単語ID][1] = TF-IDF の改良値
*/
}
}
}
void calValue(char *fn1, char *fn2)
{
FILE *fp1, *fp2;
int i, j, k, h;
double v, w;
fp1 = fopen(fn1, "w");
fp2 = fopen(fn2, "w");
// 文書数まで繰り返し
for(i = 0; i < N; i++)
{
w = 0;
// 文書数まで繰り返し
for(j = 0; j < N; j++)
VecZ[j] = 0.0;
// 繰り返し(j < 任意の文書の単語数)
for(j = 0; j < VecA[i]; j++){
h = MatA[i][j];
v = MatX[i][j];
// h = 単語ID; v = TF-IDF の改良値
// 繰り返し(k < VecB[単語ID])
for(k = 0; k < VecB[h]; k++)
VecZ[MatB[h][k]] += v * MatY[h][k];
/*
VecB : 一つの任意の単語が何個の文章に出現するのか登録されている
MatB : i(0 <= i < 文書数)が登録されている
VecZ : 一つの文書中の各単語の出現回数 * TF-IDF の改良値を単語数まで繰り返し加算する
MatY : TF-IDF の改良値
v : TF-IDF の改良値
VecZ[MatB[h][k]] += 出現回数 * TF-IDF の改良値
*/
}
// 繰り返し(k < 2)
for(k = 0; k < K; k++){
// 繰り返し(j < 文書数)
for(j = h = 0, v = 0.0; j < N; j++)
{
if(VecZ[j] > v)
{
v = VecZ[j];
h = j;
}
}
/*
VecZ[j] > v の場合 (既存の最大値より値が大きい)
v の値を VecZ[j] にする (最大値を更新)
h の値を j する (分類先をjに変更)
*/
// 近似度が高い文書をnnsk02.txtに記録
fprintf(fp1, "%d %e %s, ", h+1, v, MatN[h]);
// カテゴリー分類
if(k > 0)
MatQ[VecC[i]][VecC[h]] += 1;
if((k > 0) && (VecC[i] == VecC[h]))
w += 1;
VecZ[h] = 0.0;
}
fprintf(fp1, "\n");
// 正解ラベルと同じカテゴリーに分類できなかったファイルをclassification.txtに記録
if(w < 0.5)
fprintf(fp2, "%d %s\n", VecC[i]+1, MatN[i]);
}
// コンフュージョンマトリクスを作成する
printf("Confusion matrix\n");
printf("\t");
for(j = 0; j < C; j++)
printf("%d\t", j+1);
printf("\n");
for(k = 0; k < C; k++)
{
printf("%d\t", k+1);
for(j = 0, v = 0.0; j < C; j++)
v += MatQ[k][j];
for(j = 0; j < C; j++)
printf("%.2f\t", MatQ[k][j]/v);
printf("\n");
}
// 正答率を計算する
for(k = 0, v = 0.0; k < C; k++)
v += MatQ[k][k];
printf("Accuracy = %.2f\n", v/(N*(K-1)));
fclose(fp1);
}
void main(int argc, char **argv)
{
readValue(argv[1]); //引数はlbl.txt
readName(argv[2]); //引数はuid.txt
initData();
calTFIDF(argv[3]); //引数はtf-idf.txt
calInverted();
K = atoi(argv[4]); //引数は2
calValue(argv[5], argv[6]); //引数はnnsk02.txt, miss_uid.txt
}下記の分類結果が得られました。
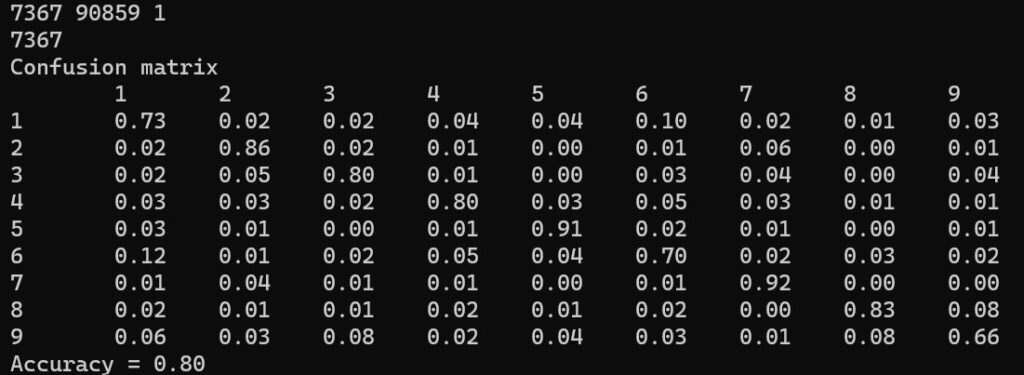
1~9の番号はカテゴリーを示しています。
- 1:dokujo-tsushin
- 2:it-life-hack
- 3:kaden-channel
- 4:livedoor-homme
- 5:movie-enter
- 6:peachy
- 7:smax
- 8:sports-watch
- 9:topic-news
左側の1~9の数字は正解ラベルのカテゴリー番号を示しています。
上側の1~9の数字はK近傍法を用いて分類したカテゴリー番号を示しています。
例えば、正解ラベルが1である文書群では、
- 正解ラベルが1である文書を、K近傍法で1に分類した割合が73%
- 正解ラベルが1である文書を、K近傍法で2に分類した割合が2%
であることを示しています。
他の箇所も同様の見方をします。
まとめ
今回は、全文書データを用いて作成した単語辞書と各文書の単語出現頻度表からTF-IDFベクトルを計算し、K近傍法による文書分類を実装しました。
正答率は80%でしたが、分類精度が高いところと低いところが幾つかあります。
次回は、分類精度が低いカテゴリーに着目し、分類を間違えてしまう要因を分析するつもりです。


