
最近の研究を調べていたら下記研究を見つけました。
文書データはlivedoorニュースコーパスを使っています。
SVMで各カテゴリーの重要語を割り出して、その重要語から各カテゴリーのラベル候補を選出しているみたいです。
つまり、現在のカテゴリー名はこうなっていますが、人間が名前を考えて付けています。
- dokujo-tsushin
- it-life-hack
- kaden-channel
- livedoor-homme
- movie-enter
- peachy
- smax
- sports-watch
- topic-news
この「カテゴリー名を考えて付ける作業」を機械に任せるとどうなるかという内容です。
先行研究では上位語を上手く取得できなかったようですが、どんな感じなのか自分もやってみます。
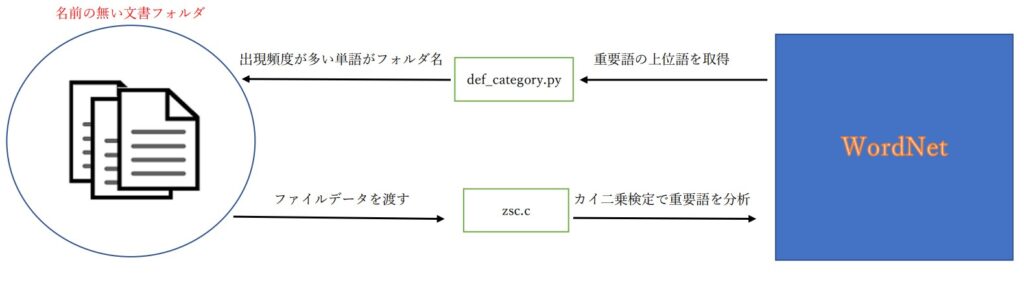
ラベル推定方法
下位手順でラベル推定をしてみます。
- カイ二乗検定で重要語を上から100個取得
- 取得した重要語の中で、WordNetに登録されていない単語は削除
- 残った重要語から各重要語の上位語を取得
- 各上位語の出現回数を計算
- 出現回数が最も多い上位語をカテゴリー名とする
上位語について
ある単語の上位概念のことです。
猫→動物
車→乗り物
蛙→爬虫類
こんな感じで重要語の上位語を取得します。
カイ二乗検定について
カイ二乗検定に関しては別の記事で説明しています。
ざっくり説明すると、単語数だけでなく、文書中に占める割合までも考慮して重要語を抽出する方法です。
WordNetについて
単語の概念辞書です。
ある単語の「意味」「類義語」「上位語」「下位語」などが定義されており、これ以外にも多くの機能があります。
今回は上位語を検索する機能を使用します。

実装
ラベル推定方法で解説した下記手順に従い、アルゴリズムを実装していきます。
- カイ二乗検定で重要語を上から100個取得
- 取得した重要語の中で、WordNetに登録されていない単語は削除
- 残った重要語から各重要語の上位語を取得
- 各上位語の出現回数を計算
- 出現回数が最も多い上位語をカテゴリー名とする
WordNet 関連はPythonの方が簡潔にコーディングできます。
そのため、手順2以降ではPythonを使用しています。
手順1
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <unistd.h>
char **MatN, **MatL;
double *VecV;
int Dm, Dn, Dc, Dk, Dh, *VecA, **MatA, **MatX, *VecY, *VecB, *VecC;
void readValue(char *fn1/* lbl.txt */)
{
FILE *fp;
int i, j, k, h;
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
fscanf(fp, "%d %d %d", &Dm, &Dn, &Dc);
VecA = (int *) malloc(sizeof(int)*Dm);
MatA = (int **) malloc(sizeof(int *)*Dm);
MatX = (int **) malloc(sizeof(int *)*Dm);
for(i = 0; i < Dm; i++)
{
fscanf(fp, "%d", &VecA[i]);
MatA[i] = (int *) malloc(sizeof(int)*VecA[i]);
MatX[i] = (int *) malloc(sizeof(int)*VecA[i]);
for(j = 0; j < VecA[i]; j++)
{
fscanf(fp, "%d:%d", &k, &h);
MatA[i][j] = k-1;
MatX[i][j] = h;
}
while((j = getc(fp)) != EOF)
{
if(j == '\n')
break;
}
}
fclose(fp);
printf("%d %d %d\n", Dm, Dn, Dc);
}
void readValue2(char *fn1/* uid.txt */)
{
FILE *fp;
int i, j, k, c[3];
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
VecY = (int *) malloc(sizeof(int)*Dm);
for(i = 0; i < Dm; i++)
{
fscanf(fp, "%d", &VecY[i]);
while((j = getc(fp)) != EOF)
{
if(j == '\n')
break;
}
}
fclose(fp);
printf("%d\n", Dm);
// for(i = 0; i < Dm; i++) printf("%f\n", VecY[i]);
}
void readValue3(char *fn1/* wid.txt */)
{
FILE *fp;
int i, j;
if((fp = fopen(fn1, "r")) == NULL)
{
printf("Unknown File = %s\n", fn1);
exit(1);
}
MatL = (char **) malloc(sizeof(char *)*Dn);
for(i = 0; i < Dn; i++)
{
while((j = getc(fp)) != EOF)
{
if(j == ' ' || j == '\t')
break;
}
MatL[i] = (char *) malloc(sizeof(char)*1023);
for(j = 0; j < 1024; j++)
{
if((MatL[i][j] = getc(fp)) == ' ')
break;
}
MatL[i][j] = '\0';
while((j = getc(fp)) != EOF)
{
if(j == '\n')
break;
}
}
fclose(fp);
printf("%d\n", Dn);
}
void calValue(char *fn1/* important_word.txt */)
{
FILE *fp;
int i, j, k;
double p, v, y;
fp = fopen(fn1, "w");
VecB = (int *) malloc(sizeof(int)*Dn);
VecC = (int *) malloc(sizeof(int)*Dn);
VecV = (double *) malloc(sizeof(double)*Dn);
for(j = 0; j < Dn; j++)
{
VecB[j] = 0;
VecC[j] = 0;
VecV[j] = 0.0;
}
for(i = 0, y = 0.0; i < Dm; i++)
{
for(j = 0; j < VecA[i]; j++)
VecB[MatA[i][j]] += 1;
// 対象のカテゴリーではない場合
if(VecY[i] != Dk)
continue;
for(j = 0; j < VecA[i]; j++)
VecC[MatA[i][j]] += 1;
y += 1.0;
}
printf("%d\n", (int)y);
// カイ二乗検定で重要語を数値化
for(j = 0, v = y*(1.0-(y/Dm)); j < Dn; j++)
{
if((p = 1.0*VecB[j]/Dm) > 0.0)
VecV[j] = (VecC[j] - y * p) / sqrt(v * p * (1.0 - p));
}
// 重要語を上位から Dh 個ファイルに記録
for(k = 0; k < Dh; k++)
{
for(j = 0, v = 0.0; j < Dn; j++)
{
// 既存の最大値 < 最大値 なら最大値を更新
if(v < VecV[j])
{
v = VecV[j];
i = j;
}
}
VecV[i] = 0.0;
//fprintf(fp, "%d %s %e (%d/%d)\n", k+1, MatL[i], v, VecC[i], VecB[i]);
fprintf(fp,"%s\n",MatL[i]);
}
// 重要語を下位から Dh 個ファイルに記録
for(k = 0; k < Dh; k++)
{
for(j = 0, v = 0.0; j < Dn; j++)
{
// 既存の最小値 < 最小値 なら最小値を更新
if(VecV[j] < v)
{
v = VecV[j];
i = j;
}
}
// printf("%d %s %e (%d/%d)\n", k+1, MatL[i], v, VecC[i], VecB[i]);
VecV[i] = 0.0;
}
fclose(fp);
}
int main(int argc, char **argv)
{
readValue(argv[1]);
Dk = atoi(argv[3]);
readValue2(argv[2]);
readValue3(argv[4]);
Dh = 100;
calValue(argv[5]);
return 0;
}手順2
import sqlite3
if __name__ == '__main__':
#データベースに接続
f1 = open("data/wid.txt", 'r', encoding="utf-8")
f2 = open("data/exist_word.txt", 'w', encoding="utf-8", newline='')
id = 1
conn = sqlite3.connect("wnjpn.db")
line = f1.readline()
while line:
#単語からそのWordIDを取得
word = line[line.find(' ')+1:line.rfind(' ')].replace('0','')
cur = conn.execute("select wordid from word where lemma='%s'" % word)
word_id = 99999999 #temp
for row in cur:
word_id = row[0]
if word_id != 99999999:
f2.write("{} {}\n".format(id,word))
id += 1
line = f1.readline()手順3
import sqlite3
import copy
import os
def read_file():
global dir_list
global file_list
root = './data'
list = []
for directory in os.listdir(root):
if os.path.isdir(os.path.join(root, directory)):
dir_list.append(directory)
path = './data' + '/' + directory
for file in os.listdir(path):
if os.path.isfile(os.path.join(path, file)):
list.append(file)
file_list.append(copy.copy(list))
list.clear()
def dfs(synset_tree):
for synset_root in synset_tree:
#上位語を検索
cur = conn.execute("select synset1 from synlink where synset2='%s' and link='hypo'" % synset_root[len(synset_root)-1])
synsets = []
for result in cur:
synsets.append(result[0])
#上位語が一つもないとき
if len(synsets) == 0:
return
#上位語が一つの場合
elif len(synsets) == 1:
synset_root.append(synsets[0])
#dfs(synset_tree)
#上位語が複数の場合
elif len(synsets) > 1:
#現在の道を(上位語の数-1)コ複製する
for i in range(len(synsets)-1):
synset_tree.append(copy.deepcopy(synset_root))
#それぞれ複製した道に複数ある上位語を一つずつ割り当てる
tree_index = 0
for hypernym in synsets:
synset_tree[tree_index].append(hypernym)
tree_index += 1
# synsetID から全ての上位語を検索し,synsetID のリストとして返す.
def get_synset_id(cur):
synset = []
synset_roots = []
for row in cur:
synset.append(row[0])
synset_roots.append([synset[0]])
return synset_roots
# 辞書の作成
def get_dict():
global dict
global path1
# WordNet に登録されている単語のリスト
file = open(path1, 'r', encoding="utf-8")
line = file.readline()
while line:
key_word = line.split(' ')
line = file.readline()
dict.setdefault(key_word[1], key_word[0])
file.close()
# 重要語をリストに登録
def get_key_word():
global key_word
global dict
global path2
# TF-IDF を使用して求めた重要語のリスト
file = open(path2, 'r', encoding="utf-8")
line = file.readline().replace('0','')
# 登録した重要語の数を数える
count = 0
# 重要語がWordNetに登録されていたらリストに登録する
while line:
if line in dict.keys():
key_word.append(line.replace("\n",''))
count += 1
if 100 <= count:
break
line = file.readline().replace('0','')
file.close()
# WordNet に登録されている単語をファイルに記録する
def write_exist_word(cur1, cur2, word):
global path3
file = open(path3, 'a', encoding="utf-8", newline='')
sub_no = 1
for row1 in cur1:
#print(row1[0])
file.write("{}:{}".format(word, row1[0] + "\n"))
'''
for row2 in cur2:
print("意味%s:%s" %(sub_no, row2[0]))
sub_no += 1
'''
file.close()
if __name__ == '__main__':
conn = sqlite3.connect("wnjpn.db")
path1 = "data/exist_word.txt"
dict = {}
key_word = []
dir_list = []
file_list = []
read_file()
dir_size = len(dir_list)
for index in range(dir_size):
path2 = "data/" + dir_list[index] + '/' + file_list[index][1]
path3 = "data/" + dir_list[index] + '/' + file_list[index][2]
# WordNetに存在する単語を登録
get_dict()
# 重要語を登録
get_key_word()
key_size = len(key_word)
for i in range(key_size):
# 単語から WordID を取得
word = key_word[i]
cur = conn.execute("select wordid from word where lemma='%s'" % word)
word_id = 99999999 #temp
for row in cur:
word_id = row[0]
if word_id != 99999999:
# WordID から synsetID を取得してパラメタ(引数)に設定
synset_roots = get_synset_id(conn.execute("select synset from sense where wordid='%s'" % word_id))
# 上位語を検索
dfs(synset_roots)
# 上位語をファイルに記録する
no = 1
for root in synset_roots:
for synsetID in root:
write_exist_word(conn.execute("select name from synset where synset='%s'" % synsetID),\
conn.execute("select def from synset_def where (synset='%s' and lang='jpn')" % synsetID),\
word)
no += 1
synset_roots.clear()
key_word.clear()手順4
def line_replace(line):
line = line.replace("\n",'')\
.replace(' ','')
return line
def read_f1(path1, path2):
f1 = open(path1, 'r', encoding="utf-8")
f2 = open(path2, 'w', encoding="utf-8", newline='')
line = line_replace(f1.readline())
list = []
pair = []
prev = ''
while line:
pos = line.find(':')
line = line[pos+1:]
list.append(line)
line = line_replace(f1.readline())
f1.close()
size = len(list)
for i in range(size):
target = list[i]
#print("{} : {}".format(list.count(target), target))
pair.append(str(list.count(target)) + ':' + target)
list.clear()
pair = sorted(pair, key = lambda x: (x[0]), reverse = True)
for i in range(size):
this = pair[i]
if this != prev:
f2.write(this + "\n")
prev = this
f1.close()
f2.close()
path1 = "data2/kaden-channel/up_entity.txt"
path2 = "data2/kaden-channel/def_category.txt"
read_f1(path1, path2)
'''
実行コマンド
python def_category.py
実行パス
"data/dokujo-tsushin/up_entity.txt"
"data/it-life-hack/up_entity.txt"
"data/kaden-channel/up_entity.txt"
"data/livedoor-homme/up_entity.txt"
"data/movie-enter/up_entity.txt"
"data/peachy/up_entity.txt"
"data/smax/up_entity.txt"
"data/sports-watch/up_entity.txt"
"data/topic-news/up_entity.txt"
'''
手順5
ノートパッドやVSCodeの機能で重要語を値が大きい順にソートします。
ラベル推定結果
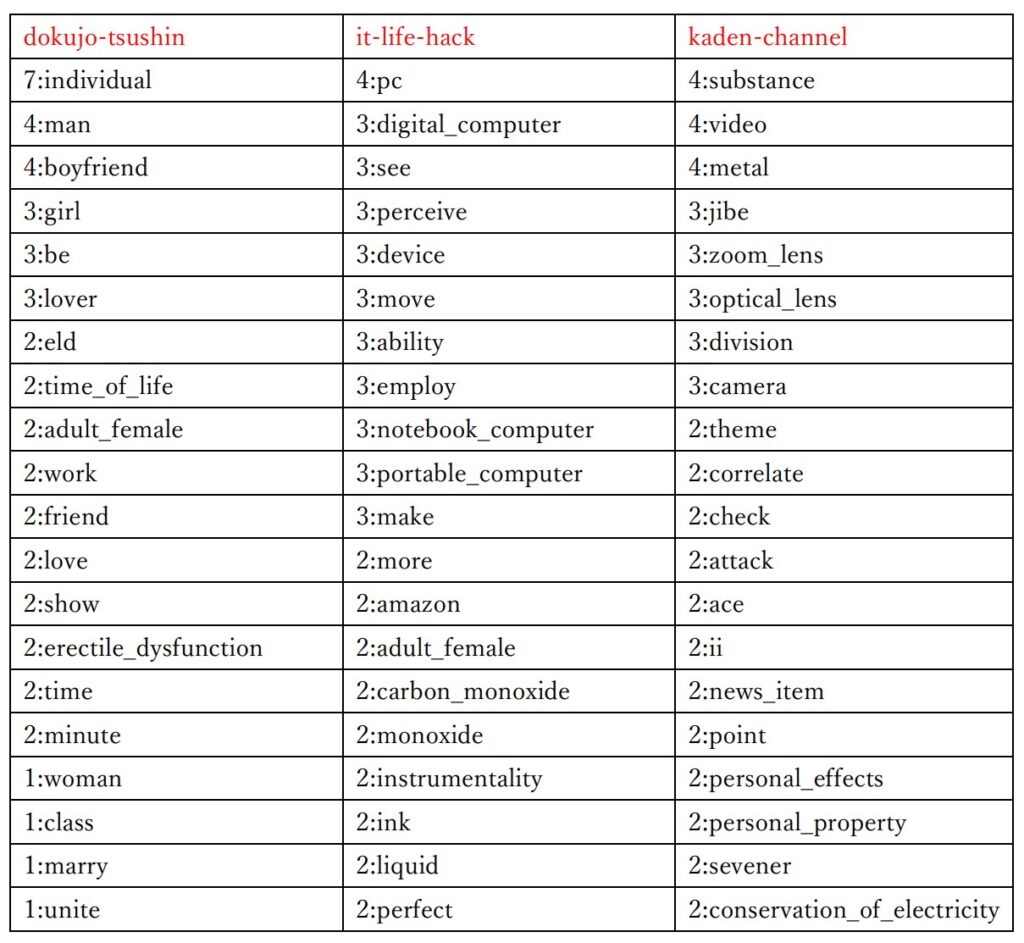
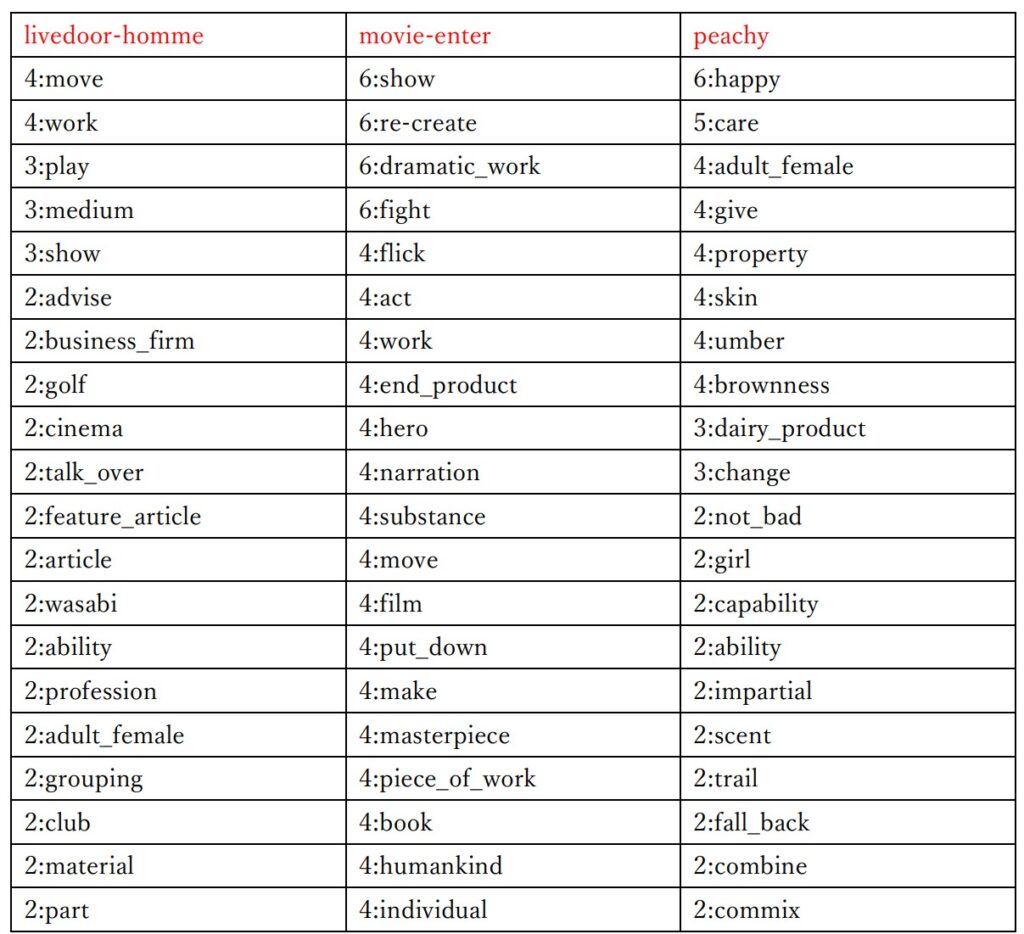
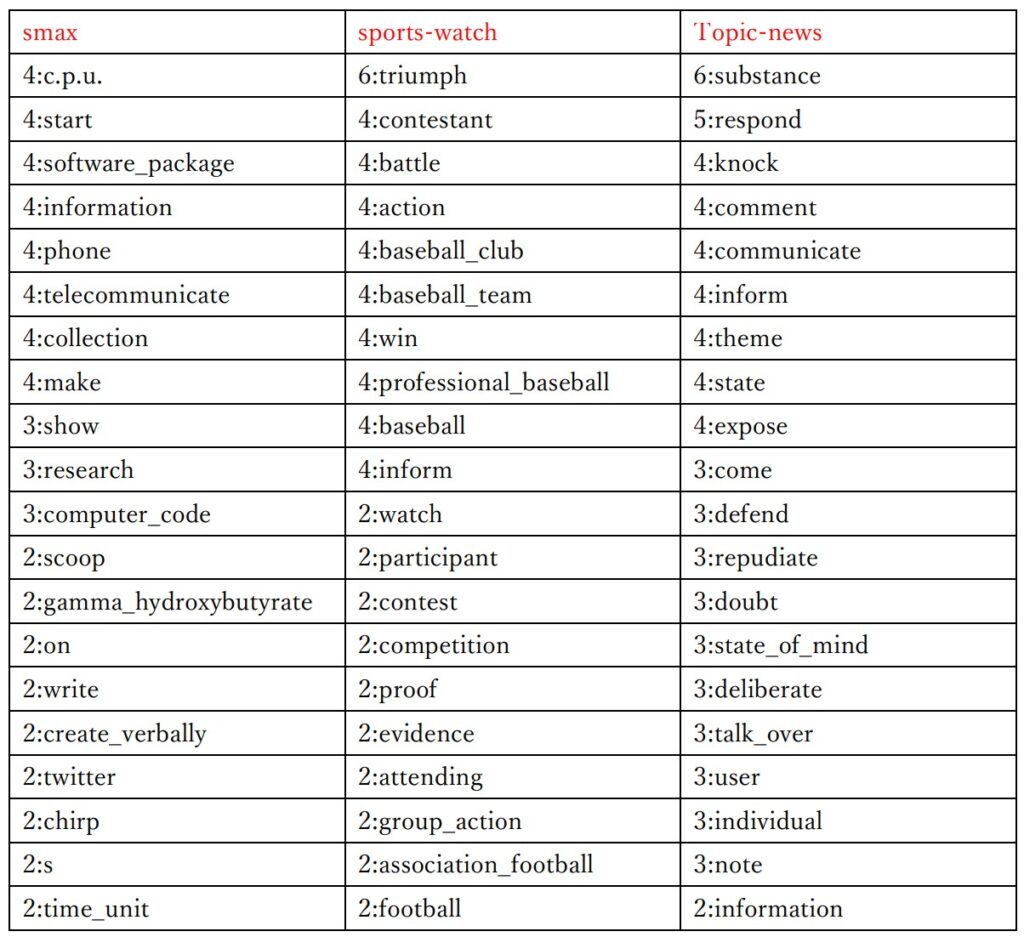
赤文字は元のカテゴリー名を示しています。
2行目以降は「出現回数:重要語」を示しています。
全体的に、まあまあ似たような意味の重要語が抽出されており、カテゴリー名として適切な重要語も存在しています。
WordNet を使用してみたのは意外とよかった印象です。
今回の結果を今後の文書検索に関する研究で活かせそうか検討してみます。
現状では、検索結果文書を可視化グラフで出力する際に組み込む方向で考えています。

